IOCCC作品集の中から、面白いコードをご紹介します^^;)
int i;main(){for(;i["]<i;++i){--i;}"];read('-'-'-',i+++"hell\
o, world!\n",'/'/'/'));}read(j,i,p){write(j/p+p,i---j,i/i);}
↑のコードをコンパイルして実行すると、以下の様な結果が表示されます。
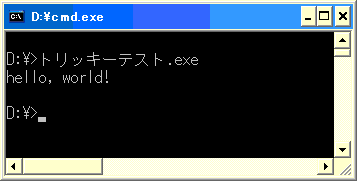 ・・・・・・・・ゴクリ。こ、これはかの有名な Hello World!!
何やら不思議なコードが書いてあり、一見 Hello Worldが表示される様には見えませんが、
・・・まぁ結果としてちゃ~んと表示されている為、早速コードを読み解いてみたいと思います。
まず、冒頭のコードに、読みやすくする為の改行&インデントを入れます。
・・・・・・・・ゴクリ。こ、これはかの有名な Hello World!!
何やら不思議なコードが書いてあり、一見 Hello Worldが表示される様には見えませんが、
・・・まぁ結果としてちゃ~んと表示されている為、早速コードを読み解いてみたいと思います。
まず、冒頭のコードに、読みやすくする為の改行&インデントを入れます。
1: int i;
2: main(){
3: for(;
4: i ["]<i;++i){--i;}"];
5: read('-'-'-', i++ + "hello, world!\n", '/'/'/')
6: );
7: }
8:
9: read(j, i, p){
10: write(j/p+p,i-- -j, i/i);
11: }
1つの文字列をソースコード上で複数行で表示したい場合(可読性向上の為等)は、
\(← 環境によって バックスラッシュ or 円マーク)を入れて改行を入れます。
つまり、
"hell\
o, world!\n"
は、
"hello World"
と同じことです。
さて、
'-' - '-' は、 アスキーコード表を見ずとも0だという事が分かります。
(数学で、「 a - a = 0 」なのと同じ理屈です^^;)
また、同様に、
'/' / '/' と i/iは、1だという事も分かります。
(「 a ÷ a = 1 」であり、 このコードでは、必ず a は0以上になる為です。)
これらをコードに当てはめてみると、以下の様になります。
1: int i;
2: main(){
3: for(;
4: i ["]<i;++i){--i;}"];
5: read(0, i++ + "hello, world!\n", 1)
6: );
7: }
8:
9: read(j, i, p){
10: write(1, i--, 1);
11: }
4行目の i [“]<i;++i){--i;}“]; は、思わず
_, ._
( ゚ Д゚)What's ?!
と突っ込みを入れそうになりますが、“]<i; ++i){--i;}“ の部分は、よくよく考えてみるとただの文字列です。
特に重要な意味を持っているわけではありません。
(試しに、4行目を i [“aaaaaaaaaaaaaa“] に置換しても、同じ結果が表示されます。)
しかし、文字列には意味が無いのですが、文字列長には意味があります。
ここでもご紹介する法則ですが、Cコンパイラにおいて、i [“文字列“] は “文字列“[i]と等価です。
その法則を利用し、i[“]<i;++i){--i;}“] を “]<i;++i){--i;}“[i] に置換します。
そして、5行目の i++を踏まえて考えてみると・・・、
“]<i;++i){--i;}“の文字列長分だけループを回し、
文字列最後のNULLに到達したところで、ループを抜ける
という作者の意図が見えてきます。
そして、もうお気づきでしょうが、
“]<i;++i){--i;}“の文字列長は、“hello, world!\n“ の文字列長と等しいです。
(これで、helloとworldの間に、不自然に,(カンマ)とスペースが入っている理由が判明しましたw)
5行目の i++ + “hello, world!\n“ も、4行目と同様の法則を使用し &“hello, world!\n“[i++]に置換します。
(※ 「&」をつけて各文字のアドレスを指定していることに注意)
10行目の writeはC言語の低水準関数です。
第一引数に1を入れた場合は、標準出力に出力します。
(write関数の詳細を知りたい方は、グーグル先生がきっと優しく教えてくれるハズ^^;)
というわけで、これらを当てはめてみると、コードは以下の様になり、
無事にHello Worldが出力される理由が判明しました。チャンチャン♪
1: int i;
2: main(){
3: for(;
4: "aaaaaaaaaaaaaa"[i];
5: read(0, &"hello, world!\n"[i++], 1)
6: );
7: }
8:
9: read(j, i, p){
10: write(1, i--, 1);
11: }
